Minimal and colorful One Page portfolio for Stockholm-based digital agency, Friends With Benefits.
by Rob Hope @robhope via One Page Love
Minimal and colorful One Page portfolio for Stockholm-based digital agency, Friends With Benefits.

Welcome to this week’s edition of the Social Media Marketing Talk Show, a news show for marketers who want to stay on the leading edge of social media. On this week’s Social Media Marketing Talk Show, we explore Snapchat Lens and Location tools with Shaun Ayala and other breaking social media marketing news of the [...]
The post Snapchat Launches First Sound Lens appeared first on .
Modern JavaScript is evolving quickly to meet the changing needs of new frameworks and environments. Understanding how to take advantage of those changes can save you time, improve your skill set, and mark the difference between good code and great code.
Knowing what modern JavaScript is trying to do can help you decide when to use the new syntax to your best advantage, and when it still makes sense to use traditional techniques.
I don’t know anybody who isn’t confused at the state of JavaScript these days, whether you’re new to JavaScript, or you’ve been coding with it for a while. So many new frameworks, so many changes to the language, and so many contexts to consider. It’s a wonder that anybody gets any work done, with all of the new things that we have to learn every month.
I believe that the secret to success with any programming language, no matter how complex the application, is getting back to the basics. If you want to understand Rails, start by working on your Ruby skills, and if you want to use immutables and unidirectional data flow in isomorphic React with webpack (or whatever the cool nerds are doing these days) start by knowing your core JavaScript.
Understanding how the language itself works is much more practical than familiarizing yourself with the latest frameworks and environments. Those change faster than the weather. And with JavaScript, we have a long history of thoughtful information online about how JavaScript was created and how to use it effectively.
The problem is that some of the new techniques that have come around with the latest versions of JavaScript make some of the old rules obsolete. But not all of them! Sometimes a new syntax may replace a clunkier one to accomplish the same task. Other times the new approach may seem like a simpler drop-in replacement for the way we used to do things, but there are subtle differences, and it’s important to be aware of what those are.
A lot of the changes in JavaScript in recent years have been described as syntactic sugar for existing syntax. In many cases, the syntactic sugar can help the medicine go down for Java programmers learning how to work with JavaScript, or for the rest of us we just want a cleaner, simpler way to accomplish something we already knew how to do. Other changes seem to introduce magical new capabilities.
But if you try to use modern syntax to recreate a familiar old technique, or stick it in without understanding how it actually behaves, you run the risk of:
In fact, several of the changes that appear to be drop-in replacements for existing techniques actually behave differently from the code that they supposedly replace. In many cases, it can make more sense to use the original, older style to accomplish what you’re trying to do. Recognizing when that’s happening, and knowing how to make the choice, is critical to writing effective modern JavaScript.
const Isn’t ConsistentModern JavaScript introduced two new keywords, let and const, which effectively replace the need for var when declaring variables in most cases. But they don’t behave exactly the same way that var does.
In traditional JavaScript, it was always a clean coding practice to declare your variables with the var keyword before using them. Failure to do that meant that the variables you declared could be accessed in the global scope by any scripts that happened to run in the same context. And because traditional JavaScript was frequently run on webpages where multiple scripts might be loaded simultaneously, that meant that it was possible for variables declared in one script to leak into another.
The cleanest drop-in replacement for var in modern JavaScript is let. But let has a few idiosyncrasies that distinguish it from var. Variable declarations with var were always hoisted to the top of their containing scope by default, regardless of where they were placed inside of that scope. That meant that even a deeply nested variable could be considered declared and available right from the beginning of its containing scope. The same is not true of let or const.
console.log(usingVar); // undefined
var usingVar = "defined";
console.log(usingVar); // "defined"
console.log(usingLet); // error
let usingLet = "defined"; // never gets executed
console.log(usingLet); // never gets executed
When you declare a variable using let or const, the scope for that variable is limited to the local block where it’s declared. A block in JavaScript is distinguished by a set of curly braces {}, such as the body of a function or the executable code within a loop.
This is a great convenience for block-scoped uses of variables such as iterators and loops. Previously, variables declared within loops would be available to the containing scope, leading to potential confusion when multiple counters might use the same variable name. However let can catch you by surprise if you expect your variable declared somewhere inside of one block of your script to be available elsewhere.
for (var count = 0; count < 5; count++) {
console.log(count);
} // outputs the numbers 0 - 4 to the console
console.log(count); // 5
for (let otherCount = 0; otherCount < 5; otherCount++) {
console.log(otherCount);
} // outputs the numbers 0 - 4 to the console
console.log(otherCount); // error, otherCount is undefined
The other alternative declaration is const, which is supposed to represent a constant. But it’s not completely constant.
A const can’t be declared without a value, unlike a var or let variable.
var x; // valid
let y; //valid
const z; // error
A const will also throw an error if you try to set it to a new value after it’s been declared:
const z = 3; // valid
z = 4; // error
But if you expect your const to be immutable in all cases, you may be in for a surprise when an object or an array declared as a const lets you alter its content.
const z = []; // valid
z.push(1); // valid, and z is now [1]
z = [2] // error
For this reason, I remain skeptical when people recommend using const constantly in place of var for all variable declarations, even when you have every intention of never altering them after they’ve been declared.
While it’s a good practice to treat your variables as immutable, JavaScript won’t enforce that for the contents of a reference variables like arrays and objects declared with const without some help from external scripts. So the const keyword may make casual readers and newcomers to JavaScript expect more protection than it actually provides.
I’m inclined to use const for simple number or string variables I want to initialize and never alter, or for named functions and classes that I expect to define once and then leave closed for modification. Otherwise, I use let for most variable declarations — especially those I want to be bounded by the scope in which they were defined. I haven’t found the need to use var lately, but if I wanted a declaration to break scope and get hoisted to the top of my script, that’s how I would do it.
The post Best Practices for Using Modern JavaScript Syntax appeared first on SitePoint.
This article was originally published on MongoDB. Thank you for supporting the partners who make SitePoint possible.
You can get started with MongoDB and your favorite programming language by leveraging one of its drivers, many of which are maintained by MongoDB engineers, and others which are maintained by members of the community. MongoDB has a native Python driver, PyMongo, and a team of Driver engineers dedicated to making the driver fit to the Python community’s needs.
In this article, which is aimed at Python developers who are new to MongoDB, you will learn how to do the following:
Let’s get started!
You can start working immediately with MongoDB by using a free MongoDB cluster via MongoDB Atlas. MongoDB Atlas is a hosted database service that allows you to choose your database size and get a connection string! If you are interested in using the free tier, follow the instructions in the Appendix section at the end of this article.
For this article we will install the Python driver called “PyMongo”.
Although there are other drivers written by the community, PyMongo is the official Python driver for MongoDB. For detailed documentation of the driver check out the documentation here.
The easiest way to install the driver is through the pip package management system. Execute the following on a command line:
python -m pip install pymongo
Note: If you are using the Atlas M0 (Free Tier) cluster, you must use Python 2.7.9+ and use Python 3.4 or newer. You can check which version of Python and PyMongo you have installed by issuing python --version and pip list commands respectively.
For variations of driver installation check out the complete documentation:
Once PyMongo is installed we can write our first application that will return information about the MongoDB server. In your Python development environment or from a text editor enter the following code.
from pymongo import MongoClient
# pprint library is used to make the output look more pretty
from pprint import pprint
# connect to MongoDB, change the << MONGODB URL >> to reflect your own connection string
client = MongoClient(<<MONGODB URL>>)
db=client.admin
# Issue the serverStatus command and print the results
serverStatusResult=db.command("serverStatus")
pprint(serverStatusResult)
Replace <<MONGODB URL>> with your connection string to MongoDB. Save this file as mongodbtest.py and run it from the command line via python mongodbtest.py.
An example output appears as follows:
{u'asserts': {u'msg': 0,
u'regular': 0,
u'rollovers': 0,
u'user': 0,
u'warning': 0},
u'connections': {u'available': 96, u'current': 4, u'totalCreated': 174L},
u'extra_info': {u'note': u'fields vary by platform', u'page_faults': 0},
u'host': u'cluster0-shard-00-00-6czvq.mongodb.net:27017',
u'localTime': datetime.datetime(2017, 4, 4, 0, 18, 45, 616000),
.
.
.
}
Note that the u character comes from the Python output and it means that the strings are stored in Unicode. This example also uses the pprint library, which is not related to MongoDB but is used here only to make the output structured and visually appealing from a console.
In this example we are connecting to our MongoDB instance and issuing the db.serverStatus() command (reference). This command returns information about our MongoDB instance and is used in this example as a way to execute a command against MongoDB.
If your application runs successfully, you are ready to continue!
MongoDB stores data in documents. Documents are not like Microsoft Word or Adode PDF documents but rather JSON documents based on the JSON specification.
An example of a JSON document would be as follows:

Notice that documents are not just key/value pairs, but can include arrays and subdocuments. The data itself can be different data types like geospatial, decimal, and ISODate to name a few. Internally MongoDB stores a binary representation of JSON known as BSON. This allows MongoDB to provide data types like decimal that are not defined in the JSON specification. For more information on the BSON spec check out its site.
A collection in MongoDB is a container for documents. A database is the container for collections. This grouping is similar to relational databases and is pictured below:
| Relational concept | MongoDB equivalent |
|---|---|
| Database | Database |
| Tables | Collections |
| Rows | Documents |
| Index | Index |
There are many advantages to storing data in documents. While a deeper discussion is out of the scope of this article, some of the advantages like dynamic, flexible schema, and the ability to store arrays can be seen from our simple Python scripts. For more information on MongoDB document structure take a look at the online documentation.
Let’s take a look at how to perform basic CRUD operations on documents in MongoDB using PyMongo.
To establish a connection to MongoDB with PyMongo you use the MongoClient class.
from pymongo import MongoClient
client = MongoClient('<<MongoDB URL>>’)
The <<MongoDB URL>> is a placeholder for the connection string to MongoDB. See the connection string documentation for detailed information on how to create your MongoDB connection string. If you are using Atlas for your MongoDB database, refer to the “testing your connection” section for more information on obtaining the connection string for MongoDB Atlas.
We can now create a database object referencing a new database, called business, as follows:
db = client.business
Once we create this object we can perform our CRUD operations. Since we want something useful to query let’s start by building a sample data generator application.
Create a new file called createsamples.py using your development tool or command line text editor and copy the following code:
from pymongo import MongoClient
from random import randint
#Step 1: Connect to MongoDB - Note: Change connection string as needed
client = MongoClient(port=27017)
db=client.business
#Step 2: Create sample data
names = ['Kitchen','Animal','State', 'Tastey', 'Big','City','Fish', 'Pizza','Goat', 'Salty','Sandwich','Lazy', 'Fun']
company_type = ['LLC','Inc','Company','Corporation']
company_cuisine = ['Pizza', 'Bar Food', 'Fast Food', 'Italian', 'Mexican', 'American', 'Sushi Bar', 'Vegetarian']
for x in xrange(1, 501):
business = {
'name' : names[randint(0, (len(names)-1))] + ' ' + names[randint(0, (len(names)-1))] + ' ' + company_type[randint(0, (len(company_type)-1))],
'rating' : randint(1, 5),
'cuisine' : company_cuisine[randint(0, (len(company_cuisine)-1))]
}
#Step 3: Insert business object directly into MongoDB via isnert_one
result=db.reviews.insert_one(business)
#Step 4: Print to the console the ObjectID of the new document
print('Created {0} of 100 as {1}'.format(x,result.inserted_id))
#Step 5: Tell us that you are done
print('finished creating 100 business reviews')
Be sure to change the MongoDB client connection URL to one that points to your MongoDB database instance. Once you run this application, 500 randomly named businesses with their corresponding ratings will be created in the MongoDB database called business. All of these businesses are created in a single collection called reviews. Notice that we do not have to explicitly create a database beforehand in order to use it. This is different from other databases that require statements like CREATE DATABASE to be performed first.
The command that inserts data into MongoDB in this example is the insert_one() function. A bit self-explanatory, insert_one will insert one document into MongoDB. The result set will return the single ObjectID that was created. This is one of a few methods that insert data. If you wanted to insert multiple documents in one call you can use the insert_many function.
In addition to an acknowledgement of the insertion, the result set for insert_many will include a list of the ObjectIDs that were created. For more information on insert_many see the documentation located here.
For details on the result set of insert_many check out this section of documentation as well.
We are now ready to explore querying and managing data in MongoDB using Python. To guide this exploration we will create another application that will manage our business reviews.
Now that we have a good set of data in our database let’s query for some results using PyMongo.
In MongoDB the find_one command is used to query for a single document, much like select statements are used in relational databases. To use the find_one command in PyMongo we pass a Python dictionary that specifies the search criteria. For example, let’s find a single business with a review score of 5 by passing the dictionary, { ‘rating’ : 5 }.
fivestar = db.reviews.find_one({'rating': 5})
print(fivestar)
The result will contain data similar to the following:
{u'rating': 5,
u'_id': ObjectId('58e65383ea0b650c867ef195'),
u'name': u'Fish Salty Corporation',
u'cuisine': u'Sushi Bar'}
Given that we created 500 sample pieces of data, there must be more than one business with a rating of 5. The find_one method is just one in a series of find statements that support querying MongoDB data. Another statement, called find, will return a cursor over all documents that match the search criteria. These cursors also support methods like count(), which returns the number of results in the query. To find the total count of businesses that are rated with a 5 we can use the count() method as follows:
fivestarcount = db.reviews.find({'rating': 5}).count()
print(fivestarcount)
Your results may vary since the data was randomly generated but in a test run the value of 103 was returned.
MongoDB can easily perform these straightforward queries. However, consider the scenario where you want to sum the occurrence of each rating across the entire data set. In MongoDB you could create 5 separate find queries, execute them and present the results, or you could simply issue a single query using the MongoDB aggregation pipeline as follows:
from pymongo import MongoClient
# Connect to the MongoDB, change the connection string per your MongoDB environment
client = MongoClient(port=27017)
# Set the db object to point to the business database
db=client.business
# Showcasing the count() method of find, count the total number of 5 ratings
print('The number of 5 star reviews:')
fivestarcount = db.reviews.find({'rating': 5}).count()
print(fivestarcount)
# Not let's use the aggregation framework to sum the occurrence of each rating across the entire data set
print('\nThe sum of each rating occurance across all data grouped by rating ')
stargroup=db.reviews.aggregate(
# The Aggregation Pipeline is defined as an array of different operations
[
# The first stage in this pipe is to group data
{ '$group':
{ '_id': "$rating",
"count" :
{ '$sum' :1 }
}
},
# The second stage in this pipe is to sort the data
{"$sort": { "_id":1}
}
# Close the array with the ] tag
] )
# Print the result
for group in stargroup:
print(group)
A deep dive into the aggregation framework is outside of the scope of this article, however, if you are interested in learning more about it check out this documentation.
Similar to insert_one and insert_many, there are functions to help you update your MongoDB data including update_one, update_many, and replace_one. The update_one method will update a single document based on a query that matches a document. For example, let’s assume that our business review application now has the ability for users to “like” a business. To illustrate updating a document with this new “likes” field, let’s first take a look at what an existing document looks like from our previous application’s insertion into MongoDB. Next, let’s update the document and requery the document and see the change.
from pymongo import MongoClient
#include pprint for readabillity of the
from pprint import pprint
#change the MongoClient connection string to your MongoDB database instance
client = MongoClient(port=27020)
db=client.business
ASingleReview = db.reviews.find_one({})
print('A sample document:')
pprint(ASingleReview)
result = db.reviews.update_one({'_id' : ASingleReview.get('_id') }, {'$inc': {'likes': 1}})
print('Number of documents modified : ' + str(result.modified_count))
UpdatedDocument = db.reviews.find_one({'_id':ASingleReview.get('_id')})
print('The updated document:')
pprint(UpdatedDocument)
When running the sample code above you may see results similar to the following:
A sample document:
{'_id': ObjectId('58eba417ea0b6523b0fded4f'),
'cuisine': 'Pizza',
'name': 'Kitchen Goat Corporation',
'rating': 1}
Number of documents modified : 1
The updated document:
{'_id': ObjectId('58eba417ea0b6523b0fded4f'),
'cuisine': 'Pizza',
'likes': 1,
'name': 'Kitchen Goat Corporation',
'rating': 1}
Notice that the original document did not have the “likes” field and an update allowed us to easily add the field to the document. This ability to dynamically add keys without the hassle of costly Alter_Table statements is the power of MongoDB’s flexible data model. It makes rapid application development a reality.
If you wanted to update all the fields of the document and keep the same ObjectID, you will want to use the replace_one function. For more details on replace_one check out the PyMongo documentation here.
The update functions also support an option called “upsert”. With upsert you can tell MongoDB to create a new document if the document you are trying to update does not exist.
Much like the other commands discussed so far, the delete_one and delete_many commands take a query that matches the document to delete as the first parameter. For example, if you wanted to delete all documents in the reviews collection where the category was “Bar Food”, you would issue the following:
result = db.restaurants.delete_many({“category”: “Bar Food“})
If you are deleting a large number of documents it may be more efficient to drop the collection instead of deleting all the documents.
There are lots of options when it comes to learning about MongoDB and Python. MongoDB University is a great place to start and learn about administration, development and other topics such as analytics with MongoDB. One course in particular is MongoDB for Developers (Python). This course covers the topics of this article in much more depth including a discussion on the MongoDB aggregation framework. Check it out here.
MongoDB Atlas is a hosted database service that allows you to choose your database size and get a connection string! Follow the steps below to start using your free database.
Follow the steps below to create a free MongoDB database:
Once you fill out the form, the website will create your account and you will be presented with the “Build Your New Cluster” pop up as shown:
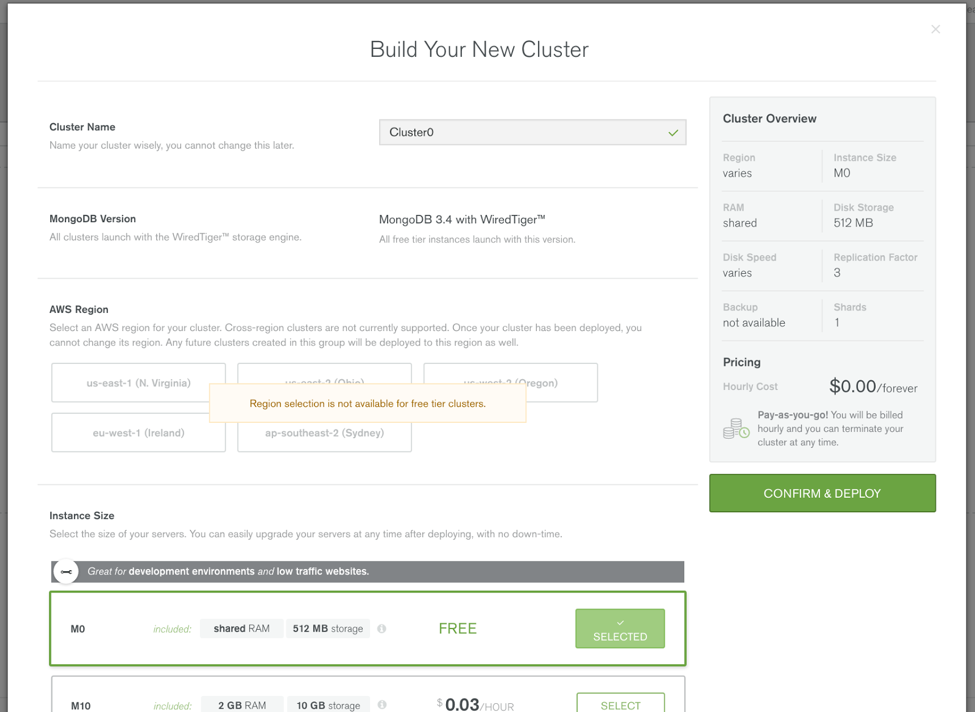
To use the free tier, scroll down and select “M0”. When you do this the regions panel will be disabled. The free tier has some restrictions, with the ability to select a region being one of them. Your database size will be limited to 512MB of storage. Given that, when you are ready to use MongoDB for more than just some simple operations you can easily create another instance by choosing a size from the “Instance Size” list. Before you click “Confirm & Deploy” scroll down the page and notice the additional options shown here:
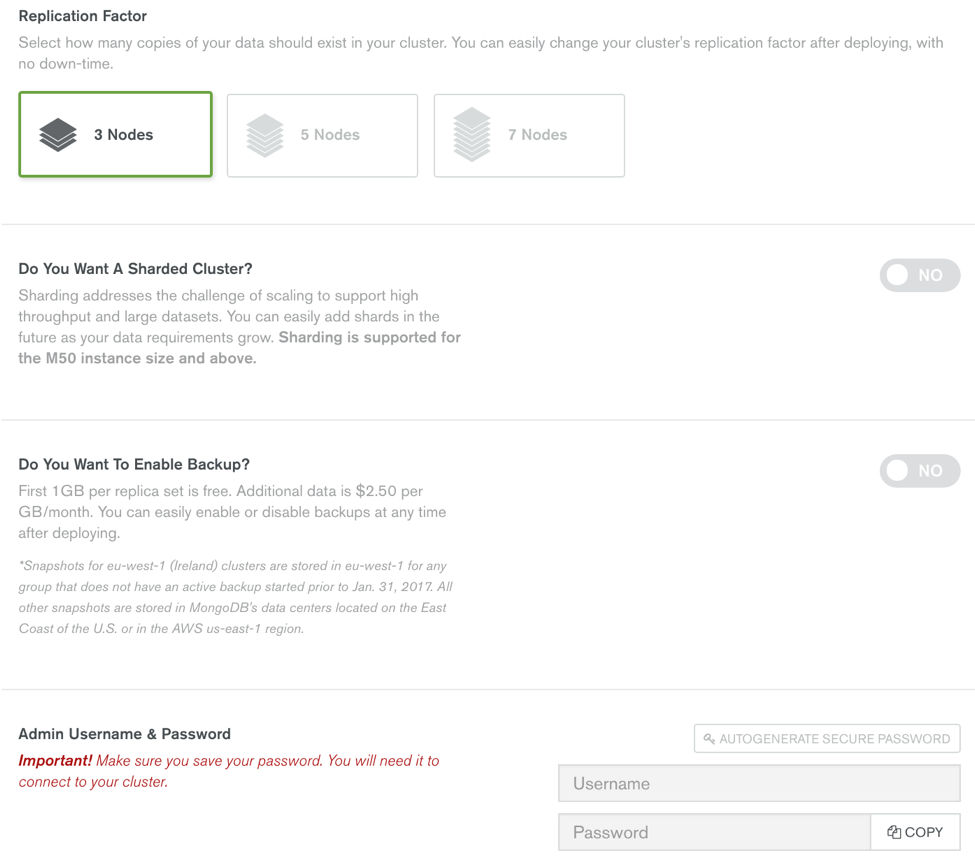
From the “Build Your New Cluster” pop up, you can see that there are other options available, including choosing a 3, 5 or 7 node replica set and up to a 12 shard cluster. Note that the free tier does not allow you to chose anything more than the 3 node cluster, but if you move into other sizes these options will become available.
At this point we are almost ready — the last thing to address is the admin username and password. You may also choose to have a random password generated for you by clicking the “Autogenerate Secure Password” button. Finally, click the “Confirm & Deploy” button to create your Atlas cluster.
While Atlas is creating your database you will need to define which IPs are allowed access to your new database, since MongoDB Atlas does not allow access from the internet by default. This list of granted IP addresses is called the “IP Whitelist”. To add the IP of your machine to this list, click on the “Security” tab, then “IP Whitelist”, and then click the “+ ADD IP ADDRESS” button. This will pop up another dialog shown below.
The post Getting Started with Python and MongoDB appeared first on SitePoint.
When using various Ethereum blockchain explorers like Etherscan to inspect addresses, you may come across certain addresses which have Transactions, Internal Transactions and Token Transfers. To understand the difference between them, we first have to understand the concept of external and internal addresses on Ethereum.
There are two types of addresses (accounts) in Ethereum: External and Internal.
When a user creates an address, that's called an external address because it's used for accessing the blockchain from the outside — from the “user world”.
When you deploy a smart contract to the Ethereum blockchain, an internal address is generated which is used as a pointer to a running blockchain program (a deployed smart contract). You can target it from the outside for calling functions, or you can target it from the inside so another deployed contract can call functions on an already deployed contract.
It's important to note that all transactions on the Ethereum blockchain are set in motion from external accounts. Even if one smart contract is supposed to call another and that one in turn calls another, the very first transaction must be done by an external account. There’s currently no way to automatically call a transaction from the outside, though solutions are being worked on.
The key difference between external and internal accounts is the following:
External addresses have private keys and can be accessed by users. Internal addresses cannot be accessed directly as a wallet, and can only be used by calling their functions.
This brings us back to transaction types. Let's inspect this address.
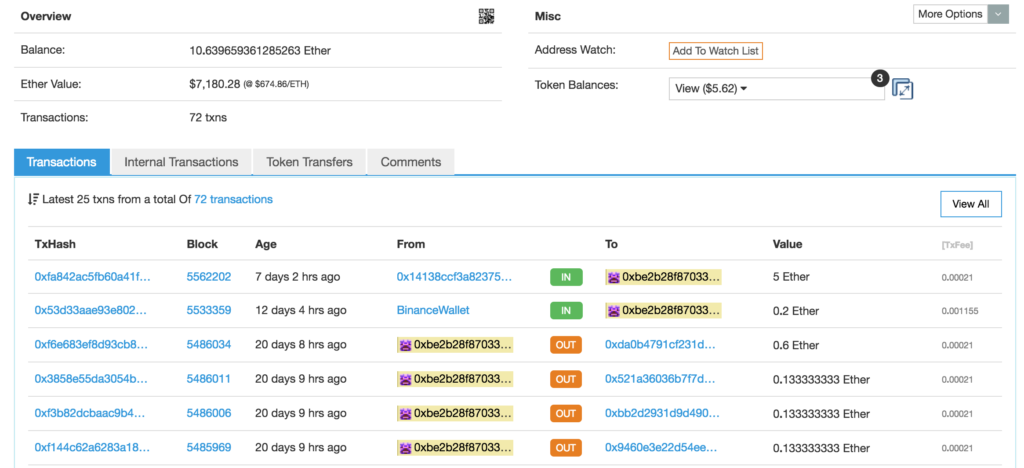
The address has several entries in the Transactions tab — some outgoing, some incoming. These transactions are external transactions — to and from external accounts. So as per the screenshot, we can see this address received 5 ether 7 days ago from this address and 0.2 ether 12 days ago from a Binance wallet. But if we look at the most recent sender, we'll see some more interesting entries:
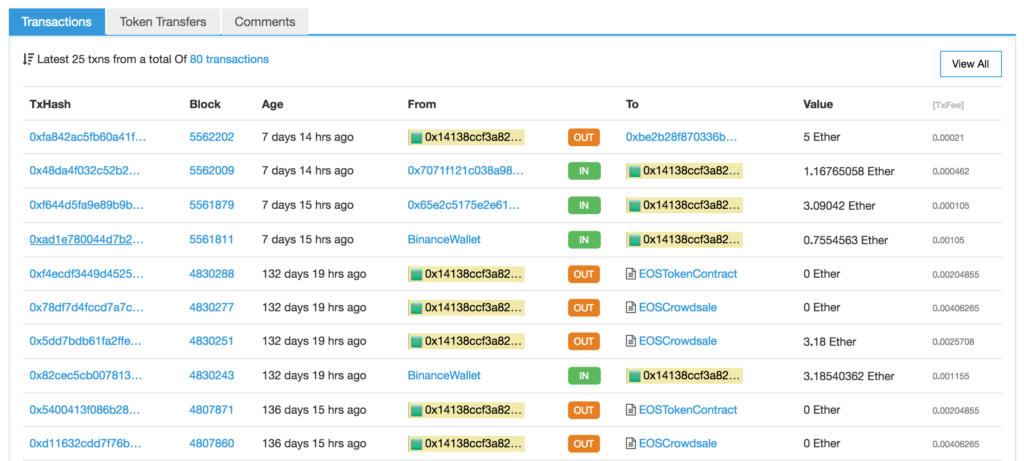
This address has been sending out Ether to individuals, but it did something else, too: it contributed to the EOS crowdsale and withdrew EOS tokens. Most of these transactions send 0 ether; they just call functions. For example, this transaction shows that almost half a year ago our protagonist called the claim function on the EOS Crowdsale contract, and this resulted in the crowdsale sending that person 312 tokens in return.
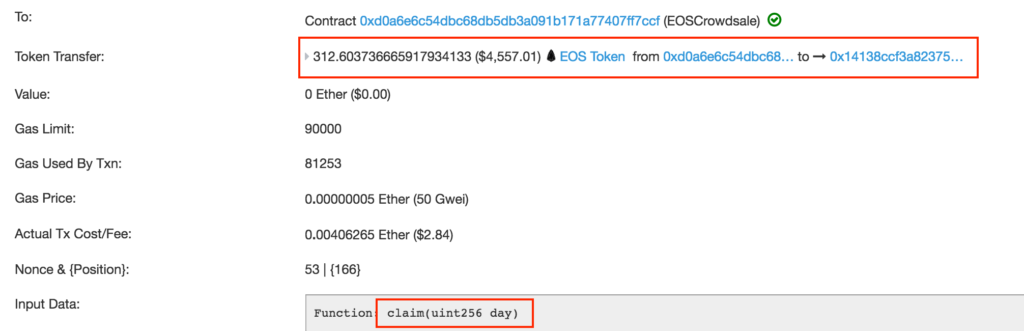
The details of this transaction don't matter much. We're just looking at it to define the Transactions tab properly:
The Transactions tab lists all transactions initiated by external accounts, regardless of who initiated them — the receiver or the sender.
Now let's look at the second tab of our first address: Internal Transactions.
Note: not all addresses will have this tab. It's only present when an internal transaction actually happened on an account.
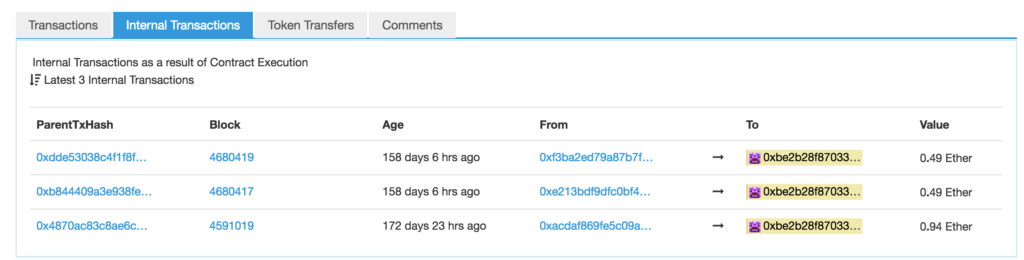
Let's look at one of these — for example, this one.
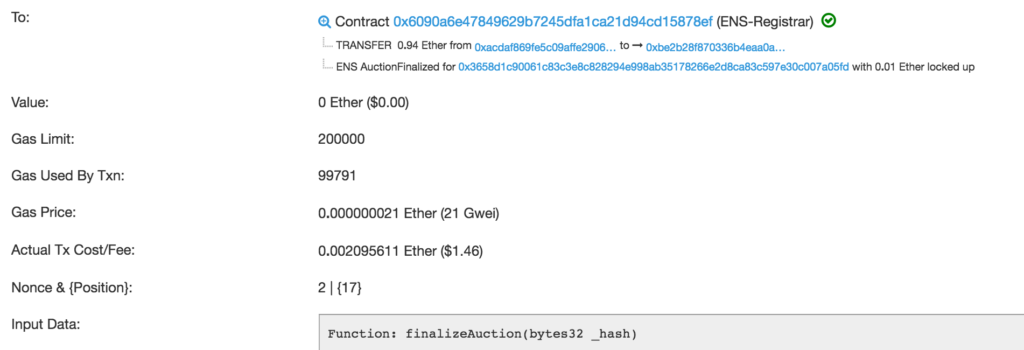
This was a bid on the ENS (Ethereum Name Service) domain service, which allows entities to register an eth domain like bitfalls.eth so people can send ether straight to it rather than to a long and cryptic address like 0xbE2B28F870336B4eAA0aCc73cE02757fcC428dC9. The transaction describes itself as being sent to the ENS-Registrar contract, which then transferred 0.94 ether to the address which initially formed the auction, and then the contract called the finalization function.
But how is this an internal transaction if it still needed to be initiated by a transaction from an external account? The original initiating TX was external, yes, but this particular transaction is just one in a chain of transactions that happened inside the blockchain, from contract to contract. As the contract automatically sent ether back due to being triggered by another contract (the ENS auction process), it was logged as an internal transaction because the transfer of ether was the result of logic that was built into the smart contract and was not sent by someone from the outside. Therefore:
The Internal Transactions tab lists all transactions initiated by internal accounts as a result of one or more preceding transactions.
The post Ethereum: Internal Transactions & Token Transfers Explained appeared first on SitePoint.
This article will show how Ethereum, rather than being just a cryptocurrency or smart contracts platform, is actually developing into a whole ecosystem.
There are four components to the post-Snowden Web: static content publication, dynamic messages, trustless transactions and an integrated user-interface. — Gavin Wood
In the 1990s, the Internet sprang into existence and, year by year, it has revolutionized the way we communicate, the way we do business, the way we consume news and TV. In many ways, it has democratized access to information, and drastically lowered global communications costs, but it has also raised the average citizen’s expectations in regards to access to communications, news, and privacy.
Websites like Wikileaks, Facebook, Twitter, in the second wave — dubbed Web 2.0 — have, along with other websites, like Youtube, Linkedin, and many personal publishing platforms like WordPress, changed the publishing of information, and made it hard to hide. Whatever news is out there is bound to be revealed, sooner or later.
Governments and officials have gone down because of this. For good and for bad, what began as leaked cables published by Wikileaks in 2010, fomented public revolt in countries like Tunisia, Libya, and sparks later turned to fires that changed the face of the Middle East. At that time, sparked by leaks of governments cables, western countries saw a series of protests as well.
In his book When Google Met Wikileaks, Julian Assange outlined often unholy links between politics, tech giants and the intelligence community. Commenting on Eric Schmidt’s and Jared Cohen’s book The New Digital Age, he rightly notes:
while Mr. Schmidt and Mr. Cohen tell us that the death of privacy will aid governments in “repressive autocracies” in “targeting their citizens,” they also say governments in “open” democracies will see it as “a gift” enabling them to “better respond to citizen and customer concerns".
The crackdown of financial institutions on Wikileaks then showed us how vulnerable to censorship we are — even in the age of the Internet.
Then came the Snowden revelations, and the public’s illusion about the actual extent to which our privacy is breached on an everyday basis was flushed down the toilet.
It was in this environment that Ethereum was created. Some months after the Snowden revelations, Gavin Wood, co-creator of Ethereum, wrote an article outlining his vision of Web 3.0 — a web which utilizes the internet infrastructure we already have, and cryptography that’s available, along with the blockchain, to build a better internet. This is to include content publishing, messaging, and value transactions — in a decentralized, censorship-proof way, with privacy guaranteed.
In the article, Wood outlines an identity-based pseudonymous low-level messaging system, a system that will give its users — both people and ĐApps — hash-based identities, privacy assurances, encrypted messages, cryptographic guarantees about senders, and messages with a defined time-to-live. This system has, for lack of a better word, modular privacy and anonymity, and guarantees of “darkness” — allowing users to opt-in or out of different privacy features. It uses the infrastructure of the Ethereum network.
Whisper is being built as a protocol, meaning that it lays the foundation for higher-level implementations, ĐApps, built on it, with different variations, using different features of the protocol, and different settings. It’s currently at POC 2 stage, being usable in current versions of geth and Parity. The usage on the mainnet is restricted by the number of running, production Ethereum nodes that have the Whisper protocol enabled. The protocol is, we can say, in alpha stage. Many specs will change.
Both Ethereum and Whisper client nodes use the ÐΞVp2p Wire Protocol for their P2P communication. In particular, the RPLx protocol is used, which is described as —
a cryptographic peer-to-peer network and protocol suite which provides a general-purpose transport and interface for applications to communicate via a P2P network.
The Node-discovery algorithm of a decentralized, censorship resistant network is its major part. Ethereum uses adapted Kademlia UDP for this, similar to Bittorrent network’s peer discovery.
Because of the evolving specs, the best place for the current definition of the protocol is Ethereum’s wiki — currently Whisper POC 2 Spec page.
Whisper combines aspects of both DHTs and datagram messaging systems (e.g. UDP).
When designing a system that aims for complete darkness — meaning guaranteed privacy and anonymity — there are performance tradeoffs. This is, we presume, the reason for the choice of UDP, which is lower level, but at the same time faster then TCP, and gives greater control.
This line from the spec that may explain many of the design decisions:
It is designed to be a building block in next generation ÐApps which require large-scale many-to-many data-discovery, signal negotiation and modest transmissions with an absolute minimum of fuss and the expectation that one has a very reasonable assurance of complete privacy.
As the spec says, there’s an important distinction between encryption of messages and pitch-black darkness, which is what the designers of Ethereum are trying to achieve. Today we know that well-funded actors are able to break privacy guarantees even of networks like Tor. For many purposes, merely knowing the destination of someone’s communication can end the needed privacy guarantees, without ever breaking the encryption of the content. (A political party insider communicating to Wikileaks would be one example.) Metadata about our communication, analyzed in sufficient, bulk amounts, can give a lot of data, and sometimes annul the effect of encrypted content.
Recent GDPR legislation in Europe somewhat reflects this.
This is why there’s a need to reach deep — to code a new system starting at a very low level.
Whisper’s POC2 promises a “100% dark operation” — which is a bold claim.
They continue:
This applies not only for metadata collection from inter-peer conduits (i.e. backbone dragnet devices), but even against a much more arduous "100% - 2" attack; i.e. where every node in the network were compromised (though functional) save a pair running ÐApps for people that wanted to communicate without anybody else knowing.
The post Ethereum Messaging: Explaining Whisper and Status.im appeared first on SitePoint.
